( 본 게시글은 작성자가 메모용으로 사용하는 용도임을 밝힙니다. 정보가 불확실할 수 있으니 참고 부탁드립니다 )
분할 정복 ( Divide and Conquer )은 여러 알고리즘의 기본이 되는 해결 방법으로, 임의의 거대하고 큰 문제를 나눌 수없을때 까지 나눠 각각의 나눈 것을 해결하여 다시 합병하고, 문제의 답을 얻는 알고리즘이다.
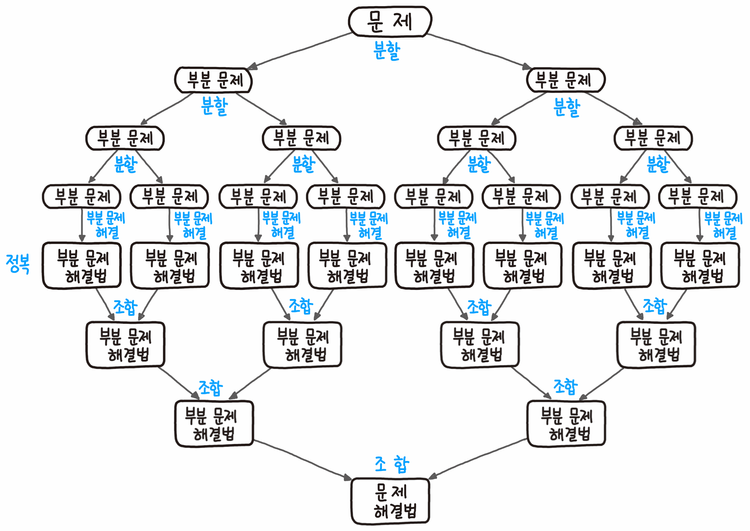
이 해결법은 당장 해결할 수 없는 큰 문제를 나눔으로써 해결할 수 있다는 장점이 있다.
명칭의 유래는 큰 문제를 작은 문제로 나눌 수 있을 때까지 나누고 ( Divide ), 나눈 문제를 해결하는 ( Conquer ) 에서 나왔다.
분할 정복의 단점으로는 분할 정복은 재귀적으로 자신을 계속 호출하면서 연산의 단위를 줄여가는 방법인데, 이 과정에서 반복적인 함수 호출로 인한 오버헤드 현상이 발생하게 되고, 기존 스택에 다른 메모리가 저장되어 있다면, 스택 오버플로우 현상도 발생할 수 있다.
분할 정복의 종류로는 합병 정렬, 퀵소트 ( Quick Sort ), 이진 탐색 등이 있다.
합병 정렬 ( Merge Sort )
합병 정렬은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
퀵 정렬 ( Quick Sort )
퀵 정렬은 특정 원소 피봇 ( pivot ) 을 기준으로 주어진 배열을 두 부분 배열로 분할하고 각 부분 배열에 대해 퀵 정렬을 순환적으로 적용하는 방식이다.

이진 탐색 ( Binary Search )
이진 탐색은 정렬된 데이터에 대해서 효과적으로 탐색을 할 수 있는 방식이다.

분할 정복과 객체 지향 프로그래밍의 유사점
객체 지향 프로그래밍은 여러 객체들의 상호작용으로 작성하는 방식으로, 만약 프로그램에 문제가 생긴다면, 문제가 일어난 해당 객체만 보수를 해주면 되고, 다른 객체에는 문제가 가지 않는 장점이 있다.
위의 분할 정복의 예시 사진에서도 보면 큰 문제를 쪼갤 수 있을때까지 작은 문제로 쪼갠 후 나눈 문제를 각각 해결하여 마지막에 해결한 문제를 모두 통합한다. 그러므로 만약 이 알고리즘에 문제가 생긴다면, 나눌 수 있을때까지 나눴기 때문에, 어느 부분에서 문제가 일어나는지 쉽게 알 수 있을 것이다.
'자료구조' 카테고리의 다른 글
| 맵 ( Map ) (2) | 2022.10.05 |
|---|---|
| 벡터 ( Vector ) (0) | 2022.10.05 |
| 다익스트라 알고리즘 ( Dijkstra Algorithm ) (0) | 2022.09.29 |
| 벨만포드 알고리즘 ( Bellman-Ford Algorithm ) (0) | 2022.09.29 |
| 깊이 우선 탐색 ( DFS )과 너비 우선 탐색 ( BFS ) (0) | 2022.09.27 |